Posted in Uncategorized on March 06, 2009 by Administrator
Embedded computing is a fast-moving field, with products, components, even whole markets coming and going on a monthly basis. The Open Source world is similar - and you often find that the problems you have at the moment are ones that other people are working on right now. Keeping a close eye on the industry gives you advance warning of up-and-coming issues, a window into the minds of your competitors and consumers, and can be a valuable source of ideas for future trends. In addition to the more traditional vendor-driver news channels, there are numerous Internet-based resources providing notification and discussion of events - ranging from aggregations of company press releases to personal ramblings by personalities driving new development. In this entry we will present a sampling of some of the resources found to be of particular and consistent interest. High-level news aggregates http://slashdot.org/ Extremely popular general news aggregation site for geek-related news, the discussion on topics of interest can offer valuable insight into the mind of the common technically-inclined consumer. http://arstechnica.com/ Well-written news site on technology-related events - could be seen as an editorial counter for Slashdot's discussion model. http://news.cnet.com/nanotech/ Cnet News network's blog focusing on news related to computer hardware. Field-specific news sites http://www.linuxdevices.com/ One of the central resources for news related to Linux and embedded devices. Low-traffic source for news releases from the small form factor computing industry. http://www.dev-monkey.com/ Occasional articles on development tools and new evaluation kits. http://www.portablemultimedia.blogspot.com/ Well-written articles focusing on news about portable devices. http://kerneltrap.org/ At one point a definitive news site on Open Source kernel development, this site still provides a easier-to-digest window into the various kernel mailing lists. http://www.embedded-computing.com/ http://cr4.globalspec.com/blog/83/Embedded-Now-Blog Embedded Computing Design magazine's blogs Personal and individual journals Personal blog of Harold Welte, known for his Linux iptables, GPL enforcement and OpenMoko work. Currently active as open source liaison for VIA Technologies. http://pavelmachek.livejournal.com/ Pavel Machek's personal journal, focusing on experiences with open source projects and the G1 Android phone. http://www.bunniestudios.com/blog/ Andrew Huang's personal blog, notable for first-hand discussions on embedded product development and the Name that Ware challenge. The lighter side of engineering http://www.electronicsweekly.com/blogs/engineering-design-problems/ Some pieces of engineering are not quite up to a standard one can be proud of. This site documents pitfalls of engineers, with examples. http://thedailywtf.com/default.aspx Insider anecdotes of how wrong software can go. There are, of course, innumerable other news sites, blogs and journals out there that are of interest in the Embedded Computing domain. Many of them are very subject-focused: dealing only with one particular product, project or the like. If you can recommend additional resources that are of general interest, however, please comment and do so.
Posted in Hardware design on February 20, 2009 by Russell Hocken
FPGAs are great devices for performance and functionality. FPGAs are primarily made up of flip flops, LUTs (Look Up Tables) and interconnect matrix. Additional to this there are often block rams, DSP blocks, fast adders, etc. LUTs themselves however offer some often unrealized design features. In most Xilinx FPGAs, the LUT is a 16x1 configuration. i.e. there are four lines in and 1 out. Internally there are 16 elements, each representing the output state for a specific input combination. Many people leave it at that and let the synthesis tools decide how best to use them. However upon closer inspection, the LUT can operate as a shift register through all 16bits, with a carry output and a programmable tap. -- see http://toolbox.xilinx.com/docsan/xilinx7/books/data/docs/lib/lib0370_356.html component SRL16E generic(INIT : bit_vector := X"0000"); port (D : in std_logic; CE : in std_logic; CLK: in std_logic; A0 : in std_logic; A1 : in std_logic; A2 : in std_logic; A3 : in std_logic; Q : out std_logic); end component; Encapsulated in modules I have made LUTs into the following * Small efficient fast counters: A single LUT can count (cycle) through 16 states. If the overall output of this is used to enable a second LUT counter, then overall one can count through 256 states. Three combined can do 1024, etc. This uses a fewer resources than if the counter were implemented in flip flops and also has the advantage that the fan in/out is less so can operate faster. To implement an arbitrary counter, a recursive module is used which takes k - the delay length and breaks it into k1*16+r1. k1 is a shorter counter that cycles 16 times, and when that is done triggers the final difference r1 (a short shift register). K1 then has the same algorithm applied to generate k2*16+r2, etc until kn is 0. * Delay paths: Delay paths are simply shift registers. Depending on the delay path, a counting implementation above may be used if only one thing can be in the path at a time. * FIFOs: the LUT shift registers form the basis of FIFOs. The FIFO length is the four address lines for the LUT * Control logic: With various control logic, the timing interdependencies can be programmed into a shift register. These implement very efficiently in a LUT. The shift register can be cyclic so it repeats forever. This has been used in an I2C controller where two parallel shift registers were used, one for the data and one for the start and stop bits. The cycle was initiated by a LUT based counter. Similar control logic has also been used for SDRAM timing which requires low latency and fan in/out. This LUT functionality can be hidden inside a module and if the code is moved to an architecture which doesn't support the LUTs being used as shift registers, a different implementation can be used
Posted in ARM Tools News on January 30, 2009 by Andre Renaud
When developing an embedded Linux system, there are a large number of choices available, not just in terms of hardware components, but also software. A Linux system is not just about the kernel, but also the user-space software layer that sits above it. Some of the most commonly chosen options are:
- Custom/Hand-built - in some ways this is probably the most common. It allows the most flexibility, and generally results in the tightest integration. It does however require the most developer effort, and the most on-going maintenance.
-
OpenEmbedded - this is a source-based Linux distribution system. In some ways it is a meta-distribution, allowing for your own customised distribution to be made. It requires a reasonable amount of initial setup effort, but once configured additional packages can be trivially added. As its named implies, this system is targeted towards embedded systems, and a lot of effort has been made to ensure it is easy to make small installations using it.
-
T2 - this is another meta-distribution, although it is not solely targeted towards the embedded market, or even only Linux. As with OpenEmbedded, it allows for a large amount of flexibility
-
EmbeddedUbuntu/ Embedded Fedora/EmDebian - Several of the larger Linux distributions have started to target the embedded market. They have the advantage of a huge existing installation and package base, but also have the disadvantage of a large amount of desktop/server baggage that generally isn't required on an embedded system.
Each of these systems has their own merits, and there is definitely no correct answer for all situations. At Bluewater, we have made the decision to go with a mixture of a custom & OpenEmbedded solution. We start with the BusyBox minimal suite of tools. This provides almost all of the standard Linux command line utilities. Using just BusyBox, and the libraries from the GCC compiler tool chain, we are able to get what we call our minimal root filesystem into around 3MB. This can be shrunk even further by using a smaller C library, and a cut-down selection of BusyBox's utilities. From this base, we then add packages using the OpenEmbedded distribution. These are easily added, and once we have built up our core repository of packages we can easily make custom filesystems for different projects. As with any development system, care must be taken not only to the suitablity of the solution with respect to the product, but also with respect to the developers using it. The wrong choice can result in a nightmarish mix of package versions and build environments, where only the most grand Linux guru can find their way out. The correct choice however results in a system as easy to manage as a desktop PC, where packages can be added and removed trivially, meaning developers are free to choose the packages that best solve their problems, rather than those that are the easiest to install.
Posted in Uncategorized on January 28, 2009 by Administrator
I don't have a Blu-Ray player yet. People tell me the best option at the moment is to get a Playstation 3, but I don't have a TV to do it justice, so have held off. I need the current TV to break first (accidentally, of course). Having said that I notice that Blu-Ray discs are starting to make an appearance at the video store, so perhaps that will push me over the edge. But at the moment, Blu-Ray is an 'early' technology, yet to hit the massive volumes of the consumer mainstream. The Cortex-R4 is in a similar position in terms of its visibility in the microcontroller market. While there are at least a dozen licensees, I believe only TI has announced a part based around it - presumably TI had a hand in the conception of the device. The Cortex-R4 is living up to its 'deeply embedded' name. Some of the features of the Cortex-R4 are:
- 8-stage pipeline (partly superscalar)
- Performance 400MHz (although 600MHz was subsequently announced)
- Resulting 600 DMIPS at 400MHz, and presumably 900 DMIPS at 600MHz
- Architecture ARMv7, including very low interrupt latency features
- Floating point unit (FPU)
- Branch prediction and prefetch
- Tightly coupled memory (TCM) aka internal single cycle SRAM, as well as caches
- Memory protection unit (MPU)
- Advanced profiling support, hardware divide, CoreSight debug and ECC memory support
The Cortex-R4 is ridiculously configurable, for example allowing three different MPU options, 3 TCM port options (with different sizes as well), selectable number of breakpoints and watchpoints and floating point or not. One can only imagine what sort of unit volumes / cost pressures might drive such extreme configurability. Not content with a single core, TI's TMS570 range includes two cores running together, although the second can be a Cortex-M3 instead. This is a serious amount of processing power for automotive applications. But ARM has aimed the chip at more than just the automotive market. Disk drives, both magnetic and optical; ink jet and laser printers, and even 3G modems. Which brings us back to Blu-Ray. Broadcom has announced that it has selected Cortex-R4 for its next-generation of Blu-Ray player chips. One point noted in the PR is that the Cortex-R4 allows the TCMs to be powered while the CPU itself is stopped. It isn't clear what this is used for - perhaps to allow data transfer to happen under DMA while processing is suspended. Broadcom's new chip is presumably a replacement for the MIPS-based BCM7440 single chip solution. The level of technology in these devices is a wonder to behold. Let's hope ARM announces a Japanese licensee this year, and perhaps someone in the disk drive market. In the meantime, I predict that the first company to put this new Cortex-R4 part into a Blu-Ray player will at last drag me into the high definition world.
Posted in Uncategorized on January 28, 2009 by Administrator
Without hardware support for screen rotation the programmer is often left to rotate the content in software before it is placed into the frame buffer. This has a considerable impact on the performance of the product. An alternative on some devices is to use DMA to do the screen rotation. This requires the DMA engine to increment the SDRAM row between pixel reads and while it frees up the processor, it uses the SDRAM very inefficiently and can have similar performance impacts as doing the entire job in software. The OMAP3530 contains hardware support for screen rotation using a rotation engine called the Virtual Rotated Frame Buffer (VRFB). This is embedded into the SDRAM Controller and can be configured to issue multiple requests to the SDRAM ensuring a maximum of consecutive accesses is performed. By tuning the VRFB to the architecture of the SDRAM the impact of page-miss penalties can be decreased and accordingly memory access performance is improved. For the programmer the VRFB provides four virtual frame buffers; 0, 90, 180 and 270 degrees. Normally the display controller is programmed to read from the unrotated location and the content to be displayed is written to the virtual address of the required rotation. 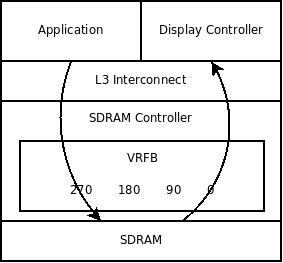 We have recently implemented this feature in our Snapper-DV product. By using the combination of hardware rotation and hardware scaling the customer can pick and choose how their content is displayed on a variety of screens. We have recently implemented this feature in our Snapper-DV product. By using the combination of hardware rotation and hardware scaling the customer can pick and choose how their content is displayed on a variety of screens.
|




